原文发表在
第一次参加天池的比赛,主要是被题目的实用性所吸引,物流货物限制品监测要求监测X光图像是否包含危险品并标出。自动化监测包裹、行李的携带品有相当广的应用前景。本文对比赛进行回顾,描述对问题的分析,方案思路以及改进和涨分点,源码分享在github。
问题分析
复赛的任务是经典的图像语义分割(semantic-segmentation)的问题,简单说就是要在像素级别将前景类别标识出来。具体到本次比赛要求将安检X光扫描图像中的5类危险品的像素分别标出来。已经有很多使用深度学习针对COCO,Cityscapes等数据集的研究,kaggle上也举办过几个图像语义分割的比赛。下面的表格列出了一些相关的研究,总体来说都是使用卷积网络构成一个encoder-decoder的结构,其中又为Unet和Mask-RCNN在kaggle中的成绩最好,所以需要重点研究一下这两个方案。
| Model | Year | Backbone | PASCAL VOC | PASCAL Context | COCO AP | Cityscapes | Kaggle Salt | Kaggle Ship | Kaggle DSB18 |
|---|---|---|---|---|---|---|---|---|---|
| SegNet | 2015 | – | – | – | – | – | – | – | – |
| FCN | 2015 | – | 62.2 | – | – | – | – | – | – |
| ParseNet | 2015 | – | 69.8 | 40.4 | – | – | – | – | – |
| Conv&Deconv | 2015 | – | 72.5 | – | – | – | – | – | – |
| UNet | 2015 | – | – | – | – | – | rank1, 9 | rank6, 9 | rank 1, 2, 4 |
| FPN | 2016 | – | – | – | – | – | – | – | – |
| PSPNet | 2016 | ResNet-101 | 85.4 | – | – | 81.2 | – | – | – |
| DeepLab | 2016 | – | 79.7 | 45.7 | – | 70.4 | – | – | – |
| DeepLabv3 | 2017 | – | 86.9 | – | – | 81.3 | – | – | – |
| Mask RCNN | 2017 | – | – | – | 41.8 | – | – | rank 10 | rank 3, 5 |
| DeepLabv3+ | 2018 | – | 89.0 | – | – | 82.1 | – | – | – |
| PANet | 2018 | – | – | – | 46.7 | – | – | – | – |
| EncNet | 2018 | – | 85.9 | 52.6 | – | – | – | – | |
| RefineNet | 2017 | ResNet-101 | – | – | – | 73.6 | – | – | |
| SAC | 2017 | ResNet-101 | – | – | – | 78.1 | – | – | |
| PSANet | 2018 | ResNet-101 | – | – | – | 80.1 | – | – | |
| OCNet | – | ResNet-101 | – | – | – | 81.7 | – | – | – |
| GALD-Net | – | ResNet101 | – | – | – | 83.3 | – | – | – |
| InPlaceABN | – | – | – | – | – | 82.0 | – | – | – |
| LinkNet | – | – | – | – | – | – | – | 1st speed | – |
方案思路
由于本次比赛限定最多使用两个模型进行融合,所以“最佳选择”是训练一个Unet和一个Mask-RCNN再进行融合:D 但是考虑到时间(三周)、计算资源和个人精力的限制,所以只能选择一个。相比较而言,Mask-RCNN在大数据集和多类别识别中的效果好,而Unet在kaggle比赛中的成绩更好,比赛的数据集相对较小、类别也少。比赛评价标准是mIoU,Unet有天生优势,因为能直接输出与图像1:1的mask,而Mask-RCNN默认输出是缩小了的。另外,Unet这种一个端到端的网络没有Mask-RCNN那么多的超参。所以X-Force优先选择基于Unet的方案。

上图是最后使用的网络结构,在Unet的基础上作了一些修改:
- 使用resnet系列作为encoder
- 将各个decoder的输出cat一起作为最终输出的特征
- 除了输出前景物体的mask,还单独输出物体的边沿
改进点(涨分点)
确定的基本方案之后,主要任务就是如何训练网络以得到更好的结果。我们都知道越大越深的神经网络的精度越高,但是需要的数据越多,训练也更困难。所以我们的基本涨分策略是研究如何训练一个大的深度神经网络,并避免过拟合。
数据增强
一些常用的图像数据增强技术是必须的,包括旋转、翻转、颜色、噪声、形变等。考虑到X光的穿透性,我们将没有危险品的图片和有危险品的图片做blend的操作 (如下图第4行),来增加数据的多样性。

快速训练 :progressive image sizing
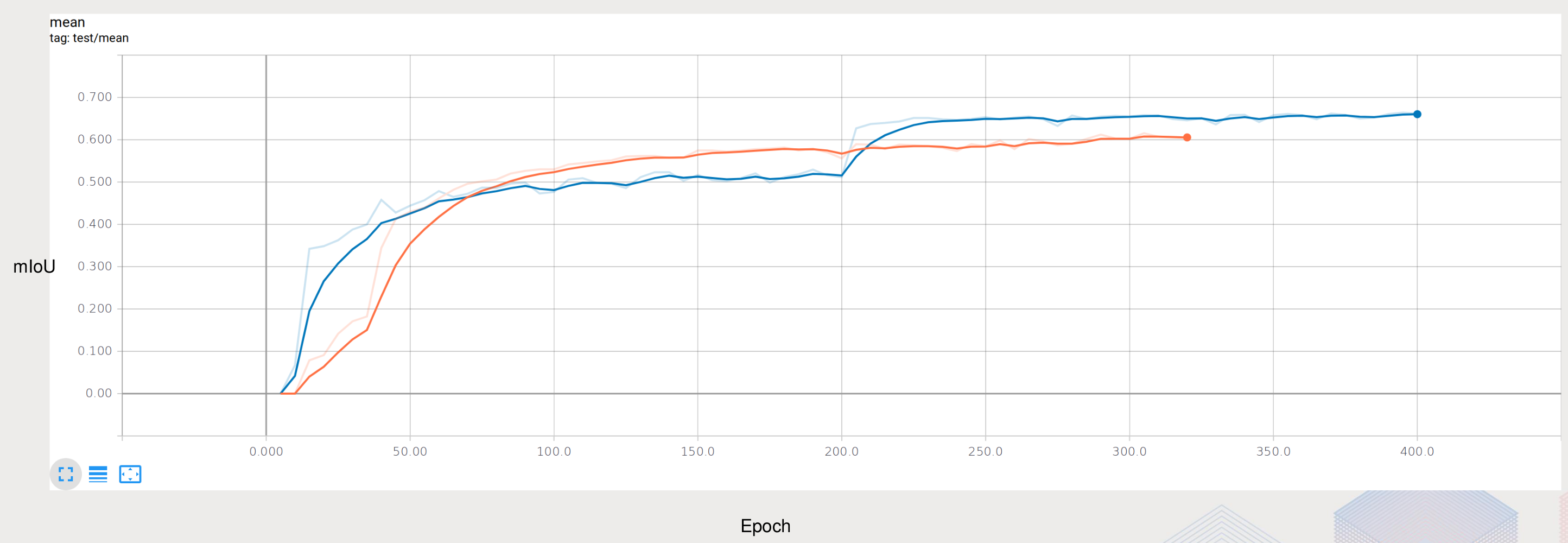
训练时间太长常常是训练深度神经网络的大问题,考虑到比赛的截至时间,训练速度直接决定了开发的迭代速度和实验的总次数。所以这次比赛我使用了一些加速训练的方法,包括多卡分布式训练,混合精度训练和progressive image sizing。
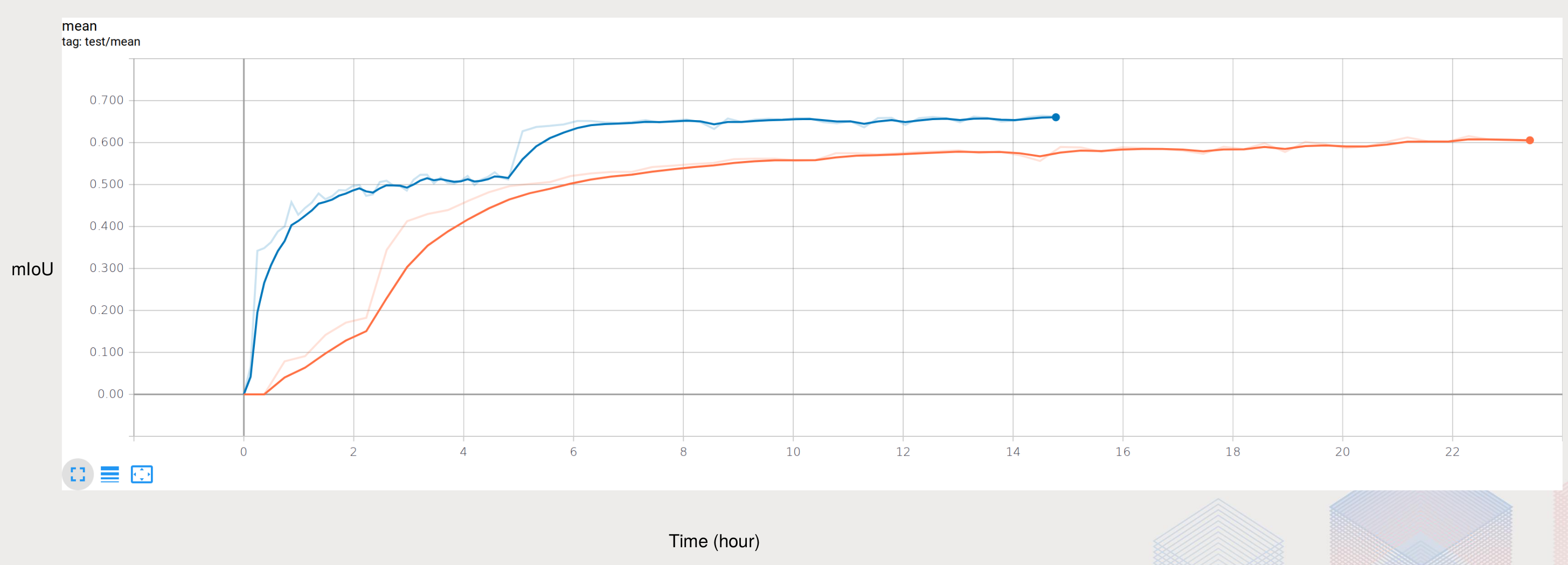
progressive image sizing 就是在训练的初期使用比较小的图像作为输入,然后再使用较大的图像作为输入。这个过程就像人学习一样,先从简单的、粗略的开始学起,然后在学习复杂的、精细的,这样最后网络收敛会更快、更好。下图中橙色为使用尺寸为256的图像作为输入,蓝色的为先使用128p图像,再使用256p图像。
下面这张图直接对比两次训练使用的时间差别
提高模型泛化能力
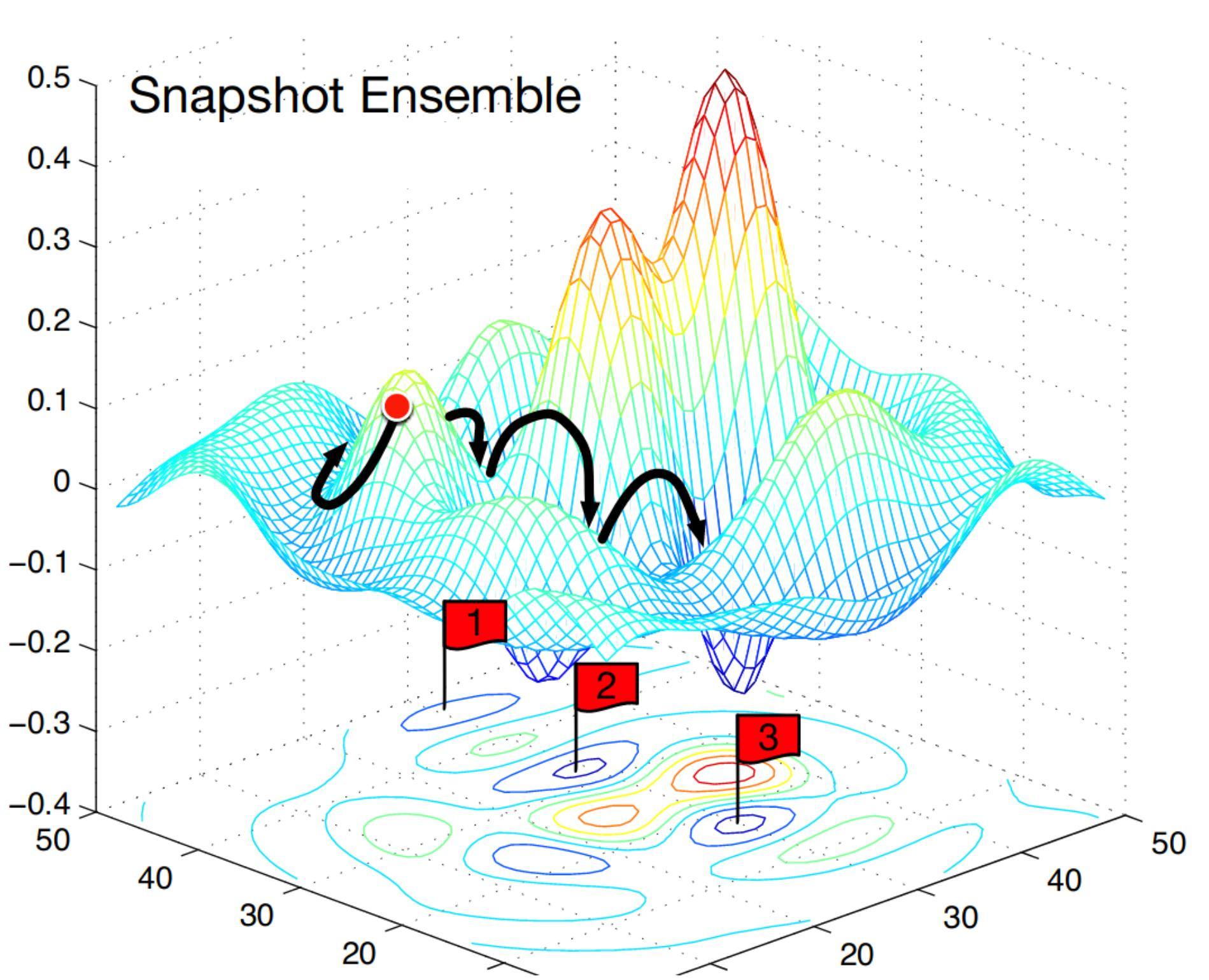
snapshot选取和融合
因为数据集比较小,即使使用了各种数据增强技术,训练使用以senet154作为encoder这样大网络,选取一个snapshot作为最终模型的参数还是会有过拟合的风险,选取多个snapshot使用参数均值的方法对模型参数进行融合可以提高模型的泛化能力。但是传统的方法是对一个模型进行多次训练来取得多个snapshot,这会需要很多的计算时间。我采用根据不同评价标准选择融合的候选参数的方法,也就是选择最小验证loss,最大mIoU,和训练最后(通常是训练loss最小)的三个模型参数进行融合。
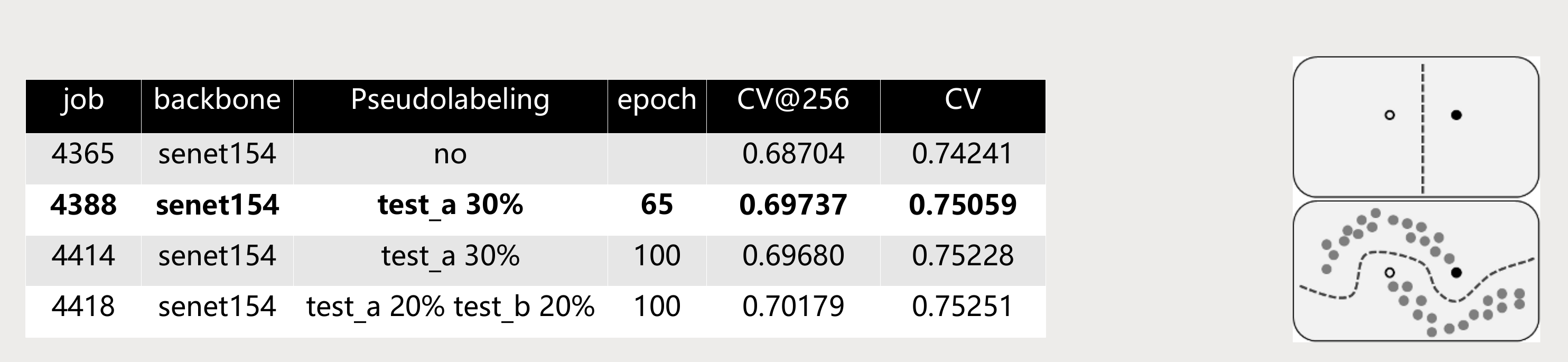
半监督学习 semi-supervised learning: pseudolabeling
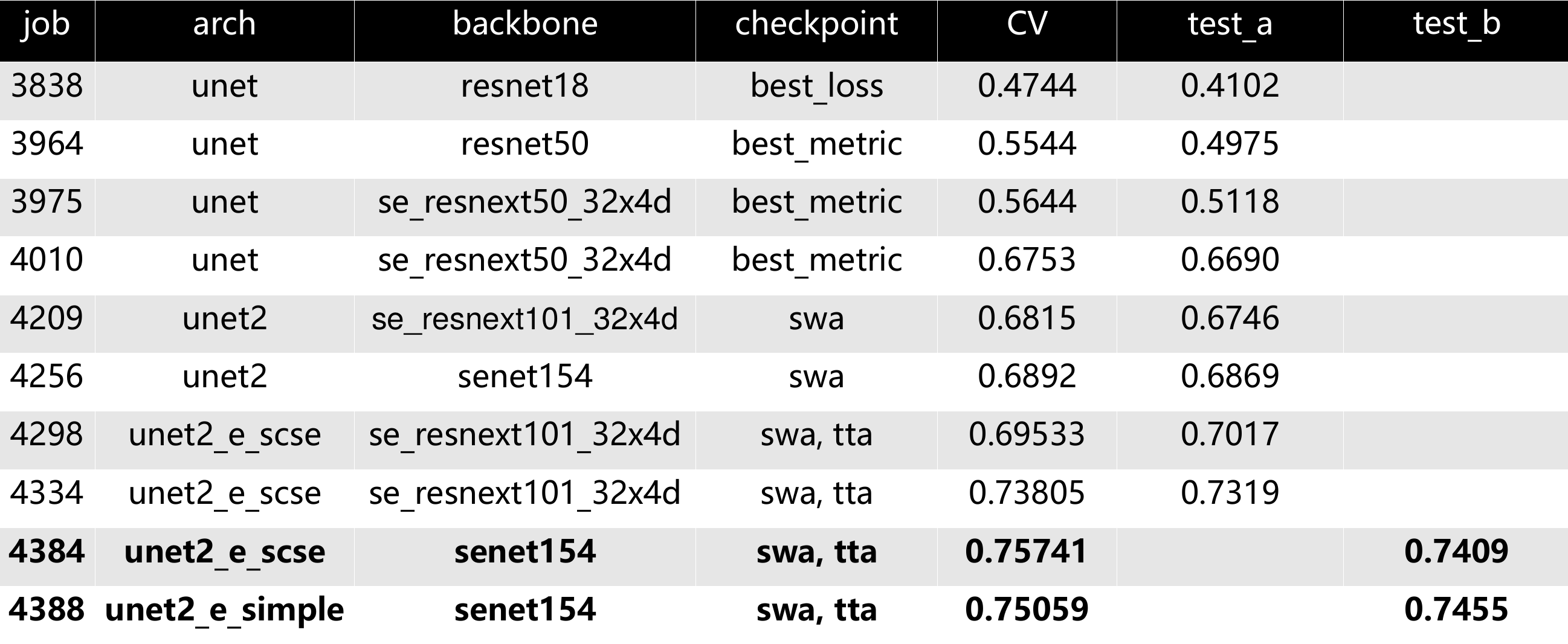
pseudolabeling即使用已训练的模型在测试数据上的结果作为训练数据,来达到增加数据集、进而提高模型精度的方法。右下图是pseudolabeling的示意图,左边的表格为pseudolabeling使用test_a的数据对于模型精度的提升,job4388 模型为最终提交的test_b和test_c的模型,这是因为比赛时间的限制,只训练了65个epoch,后面两个模型是比赛之后的实验结果,加上test_b的数据之后精度还能提高。
测试增强
在测试时,通过对图像的旋转和翻转,并对结果取平均也能提高精度,如下表。
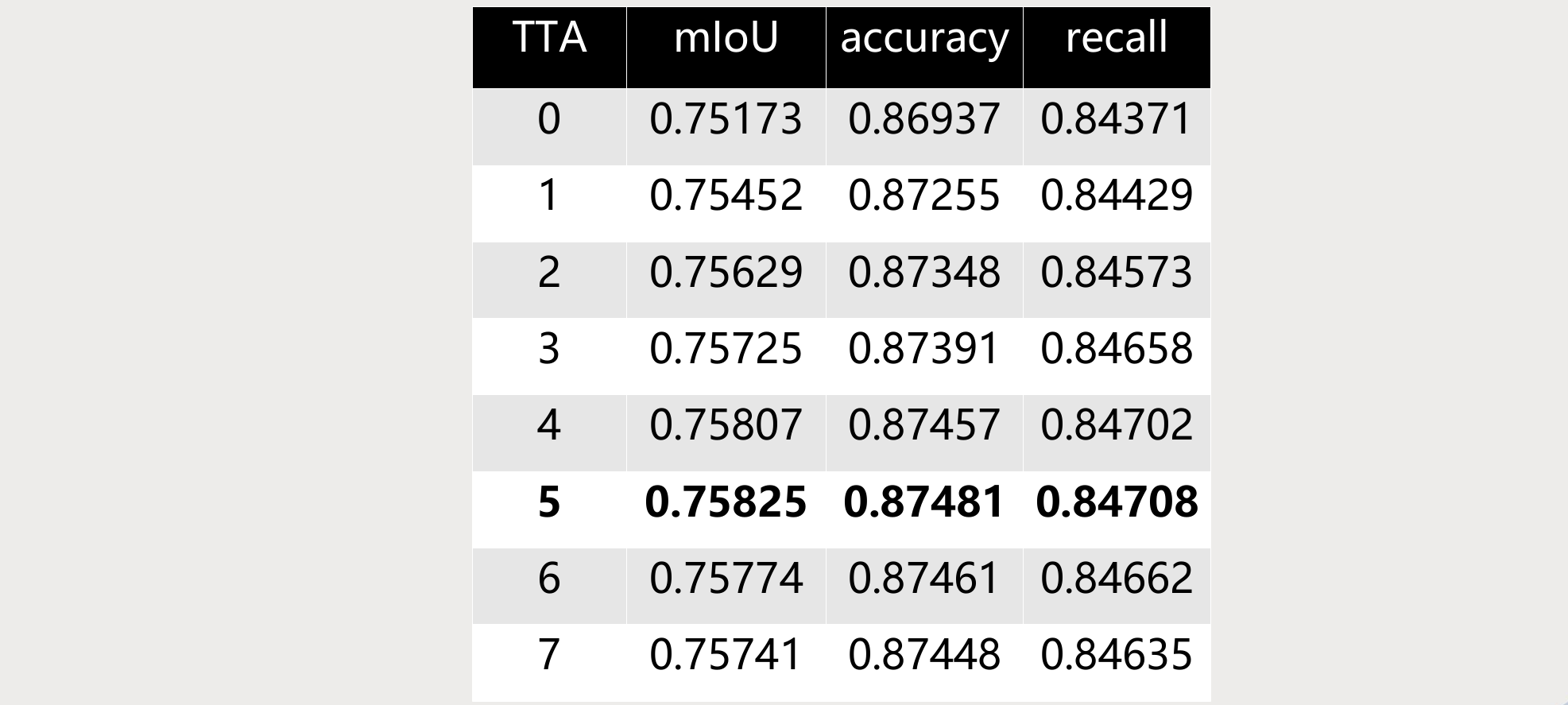
但是这样推理测试的速度慢了8倍,考虑到数据中有很多图片没有危险品,而测试增强对于这些图片没有改进,所以避免对这些图片多次测试可大幅提高测试速度。代码改动也和少,赛后我测试了这个想法:

总结
- 端到端的一体化网络设计,方便使用不同大小的预训练网络
- 使用逐步增加训练图像大小等方法,提高训练速度和精度
- 使用数据增强、模型参数均值、半监督学习的方法提高模型泛化能力
- 使用测试增强提高结果精度(并优化)
下表为在本次比赛中的一些实验结果: